本文收录了在ResNet之后出现的性能较好的深度学习网络,本篇侧重于有注意力机制的网络,有:SENet、SKNet、CBAM、Non-local Net、GCNet、BAM、SGENet和SRMNet。网络中更倾向于提取重点关注的特征而减少其他部分的影响,具体网络的构成和实际实现应参考论文。
SENet
论文: Squeeze-and-Excitation Networks
代码: Caffe TensorFlow Pytorch
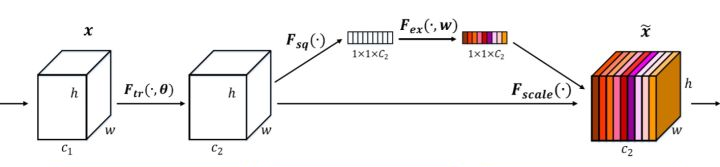
包括ResNet在内之前的很多网络都是从空间维度上提升网络的性能,而SENET企图找到通道之间的关系以提升性能。其关键步骤为压缩(Squeeze)和激活(Excitation)。
在压缩步骤中,把维度为H*W*C的原始特征压缩为1*1*C,实际应用一般使用global average pooling;
在激活步骤中,一般使用两个全连接组成Bottleneck来建模通道间的向相关性,最后使用sigmoid归一化。把经过压缩和激活步骤得到的1*1*C的向量当作权重,加权到原始特征的每一个通道中。
这个压缩和激活步骤可以和Inception和ResNet模型结合得到更好的性能。
SKNet
论文: Selective Kernel Networks
代码: Caffe TensorFlow Pytorch
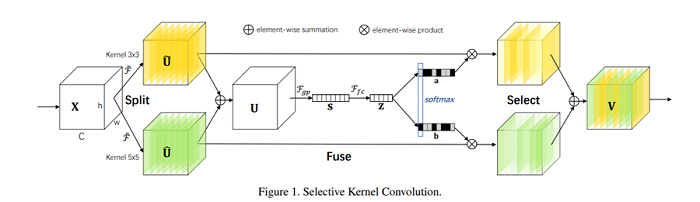
SKNET的想法是针对输入信息的多个尺度进行调节,其关键步骤有三个:拆分(split)、融合(Fuse)、选择(Select)。
在拆分步骤中,输入被两个不同大小的卷积核分别卷积得到两个特征。
在融合步骤中,将卷积得到的两个特征相加,进行SENET中的压缩和激活步骤,得到不同通道的权值,与SENET的区别是,权值大小为1*1*2C,权值平分为两个部分,对应两个特征,在归一化的时候是一起归一化的所以两部分的权值和等于1。
在选择步骤中,先按照两个部分的权值分别对原始卷积得到的特征乘上加权,再按照两部分的权值和合并两个尺度的特征。
这三个步骤同样可以与Inception和ResNet等模型结合得到更好的性能。
CBAM
论文: Convolutional Block Attention Module
代码: TensorFlow Pytorch
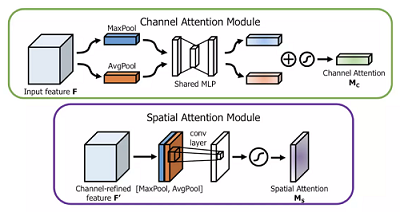
类似于SENET针对通道的注意力机制,CBAM结合了通道和空间的特征关系。一个基础的CBAM模块包括两个部分:通道注意力模块和空间注意力模块。
通道注意力模块分别使用Max Pool和Avg Pool对原始特征H*W*C池化成1*1*C,池化后的结果分别经过多层感知机,相加再Sigmoid归一化得到通道权值,对原始特征点积加权即可。
空间注意力模块分别使用Max Pool和Avg Pool在通道维度上得到H*W*1的两个特征,并在通道维度拼接成H*W*2,经过卷积操作降维成H*W*1,最后Sigmoid归一化得到空间权值,对之前的特征点积加权即可。
这两个操作可以嵌入到VGG和ResNet等网络得到更好的效果。
Non-local Net
论文: Non-local Neural Networks
代码: Caffe TensorFlow Pytorch
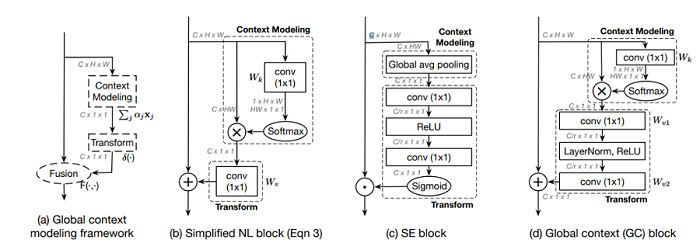
一般的网络卷积的时候感受野只有卷积核大小,为了增大感受野、引入全局信息提出了Non-local非局部区域的神经网络。
非局部操作的公式为,其中是需要提取特征的位置,是周边非局部的位置;函数用于衡量位置和位置的关系,越小表示位置对位置影响越小;用于计算输入信号在位置的特征值,是归一化参数。
下图为非局部操作在网络中的结构,对于图像,下图的N=1,函数采用的是嵌入式高斯。可以看到加入了类似残差的结构从进行卷积与原特征相加得到,这样更方便插入现有网络。
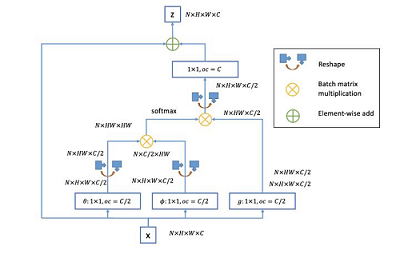
GCNet
论文: GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond
代码: TensorFlow Pytorch
GCNet比较了Non-local和SENET,并提出了一个整合优势的网络。
GCNet首先简化了Non-local的网络,一是省去了函数中对位置的卷积部分;二是省去了残差结构中不再对提取特征卷积而是直接相加。
然后GCNet再其中加入了SE结构,有四点区别:
一是简化的Non-local网络在与原特征相加前是一个1*1*C的向量,以此代替了SE结构中的压缩步骤;
二是取消了SE结构中的Sigmoid;
三是在ReLU处加入了LayerNorm;
四是与原特征合并的时候将加权的点乘改成了直接相加。
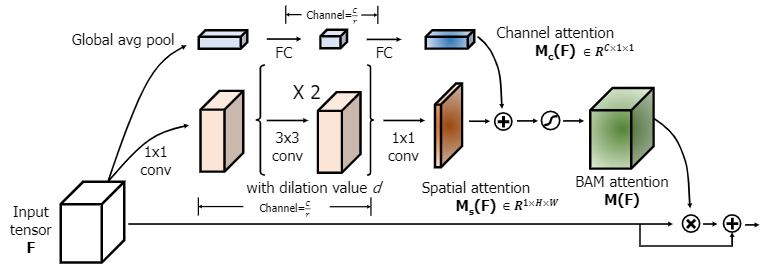
BAM
论文: Bottleneck Attention Module
代码: TensorFlow Pytorch
BAM设计作为BottleNeck放在了ResNet每个Stage之间。与CBAM类似,融合了通道注意力模块和空间注意力模块,不过CBAM两模块是串联的,而BAM是并联的。
通道注意力模块简化得与SE模块几乎一致,压缩只使用Avg Pool;
空间注意力模块将普通卷积换成了空洞卷积,提高感受野。
两注意力模块相加合并Sigmoid归一化成为BAM注意力与原特征相乘合并,最后加上原特征。
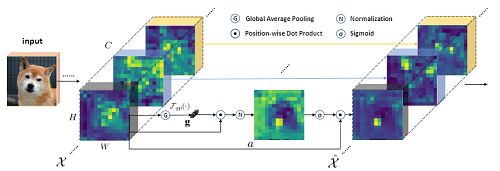
SGENet
论文: Spatial Group-wise Enhance: Enhancing Semantic Feature Learning in Convolutional Networks
代码: Pytorch
SGENet借鉴了SENet,生成的注意力向量仅由通道分组后的全局特征和局部特征之间的相关性决定,使得网络变得轻量。
原特征图像首先像SE结构那样通道分组,进行global pooling,得到注意力权值向量。然后将这个权值向量与原特征加权点积,得到的特征经过BN层,再进行Sigmoid归一化。最后将归一化的结果再次与原特征点积得到最终输出。
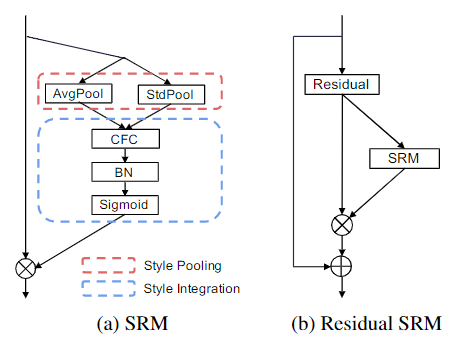
SRMNet
论文: SRM: A Style-based Recalibration Module for Convolutional Neural Networks
代码: Pytorch
SRMNet受到SENET的启发,但更关注于图像的样式(纹理)。一个SRM模块分成两部分:样式池化和样式整合。
在样式池化阶段,论文采取了Avg Pool和标准差两种样式提取方式从各通道得到了两个样式向量;
在样式整合阶段,两个样式拼接后经过一个全连接层和一个BN层得到通道数大小的样式权值向量。最后把这个样式权值向量与原特征加权相乘即可。